Before discussing on our reliable transmission protocol, we have a brief survey on several low-latency communication packages with regard to how they handle the reliability issue. Existing low-latency communication systems for clusters fall into two main families. One is based on programmable network devices, such as Myrinet and GigaNet [39], which make use of the embedded co-processors to offload the host processors in running their customized messaging protocols. Another type is based on non-programmable network devices, such as Fast Ethernet and ATM, which rely on the host processors to carry out their customized messaging protocols. In the following discussion, we use the Myrinet-based systems as the representatives of the first type, and the Ethernet-based systems as the representatives of the second type of messaging systems.
To support reliable communication, we have implemented a user-level
reliable transmission layer atop of DP. From our experiences, we observed
that modern networking technologies are quite reliable, as almost
all data loss problems happened in the network are due to the congestion
problem. As we believe that by using our communication model, we can
devise efficient schedules to avoid congestion problem for most of
the collective communications. To keep the reliable layer as lean
as possible, we try to avoid unnecessary memory copy. Thus, we adopt
the in-order accept policy [92] on the receiver side
so as to reduce the ![]() overhead, and a variant of Go-Back-N
ARQ as the error recovery scheme on the sender side.
overhead, and a variant of Go-Back-N
ARQ as the error recovery scheme on the sender side.
Another commonly used ARQ is the Selective-Repeat ARQ [92].
With this scheme, the only frames retransmitted are those that receive
a negative acknowledgement. Although Selective Repeat ARQ provides
better retransmission strategy, it requires complex buffer management
and/or an extra memory copy for handling out-of-order data arrival.
Therefore, this becomes costly if the underlying architecture does
not support it. For example, to implement selective repeat ARQ on
top of DP, we need to have an extra memory copy (![]() ) and
an extra buffer pool which is large enough to temporarily buffer all
out-of-order arrivals. Since we believe that with well-coordinated
and well-scheduled communication schemes, congestion loss would be
rare. This could not justify for consuming extra resources and adding
extra overheads to the lightweight messaging system.
) and
an extra buffer pool which is large enough to temporarily buffer all
out-of-order arrivals. Since we believe that with well-coordinated
and well-scheduled communication schemes, congestion loss would be
rare. This could not justify for consuming extra resources and adding
extra overheads to the lightweight messaging system.
Go-Back-N ARQ is a fairly straight-forward protocol and has been adopted in other lightweight messaging systems, e.g. [96,113]. However, simple variations of the protocol could have significant impact on the final performance under congestive loss situation. For example, TCP is basically one type of ARQ protocoltypeset@protect @@footnote SF@gobble@opt The TCP protocol (specified in RFC 793 [85]) does not define the accept policy on the out-of-order data arrival and the retransmission policy on the error recovery, therefore, we could have a Go-Back-N like TCP if a particular implementation uses In-order accept policy and Batch retransmit policy (page 663 in [92]). However, most of the implementations adopt the Selective Repeat ARQ approach. , however, its complexity and importance on the Internet has attracted lots of researches and investigations within the past decades [74,63,84]. Before we layout our analyses on how different buffering architectures affect on the congestion behavior, we need to provide a clear picture on the GBN protocol that we are using.
|
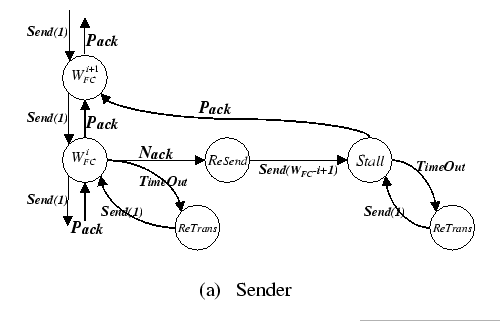
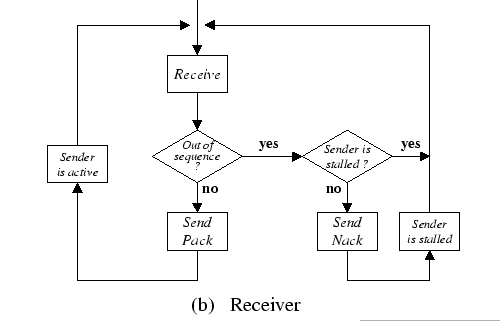
Figure 4.1 shows the state transition diagram of the sender and the logic flow diagram of the receiver according to this GBN protocol. When the sink process receives a packet, an acknowledgment may or may not be sent out that depends on (1) the current state of the source with respect to this sink, (2) the validity of this packet, and (3) instruction from upper level application. One of the design goals of this reliable layer is for efficient implementation of structural communication schemes, e.g. collective communication. Therefore, we provide a mechanism for higher level application to decide on the most effective acknowledgment methods, such as having immediate acknowledgment, piggyback acknowledgment, or delay acknowledgment whenever possible.
There are two types of acknowledgments. An in-order packet will result in a positive acknowledgment (Pack), otherwise, a negative acknowledgment (Nack) is generated. This Nack packet becomes a loss signal to the source when an out-of-sequence packet is detected, then this packet is simply dropped. Now the receiver labels this sender as has transited to the Stall state, and all subsequent out-of-sequence packets from this sender will be discarded unconditionally without generating any more negative acknowledgements. This receiver only resumes the acknowledging process until it receives the first in-order packet from the corresponding sender. The rationale behind this approach is to minimize the number of control packets. Even though control packets are small-size packets, they still consume network resources, e.g. network buffer and host receive buffer, which are critical resources under the congestion situation.
On the other side, whenever the source process receives a Pack packet, it advances its sliding window, and thus, allows injection of one more packet to the network. Error situations are detected at the sender side by either receiving a Nack packet or a timeout situation is raised. On receiving a timeout incident, the sender retransmits the corresponding packet and reset its timer. On receiving a negative acknowledgement, the sender backs up to the first error packet (indicated on the Nack reply) and resends all outstanding packets. Then it transits into the Stall state. Under the Stall state, the sender stops sending out new packets until the first Pack reply is returned from the receiver, then it transits back to the normal transmission state. Otherwise, it waits for the timeout situation and retransmits those timeout packet(s).
The unique features of this reliable transmission protocol are the use of fast retransmission mechanism and the present of the Stall state. Although standard GBN protocol is known to be inefficient if error rate is high, we believe that under well-organized communication schedules, the probability of having error situations is extremely low. Moreover, we still attempt to improve the error recovery path in a way that the extra work-done would not hurt the performance of the common/fast path, but would improve the performance of the GBN protocol under heavy congestion. First, we make use of the negative acknowledgement to serve as a quick recovery signal which is similar to the use of triple-duplicate acknowledgement in the Fast Retransmit [93] scheme of TCP protocol. By this method, the protocol optimistically retransmits all outstanding packets without waiting for the retransmission timer to expire. The rationale behind this scheme is, since the receiver receives some out-of-sequence packet(s), the network congestion problem may not be too severe, thus the sender tries to recover from the loss immediately.
If the network congestion problem is really harsh, the influx of retransmission packets will make it even worst as we are using the GBN strategy. In order to avoid wasting of bandwidth, when a communicating pair fails to resynchronize themselves by using the fast retransmission, the protocol refrains the sender by keeping it in the Stall state. Now the sender cannot send out any packet until the retransmission timers expire, thus, reduces the traffic load. With the decrease in network load, we hope that the congestion problem would be resolved soon, and the sender could resume the transmission after idling for a timeout interval.