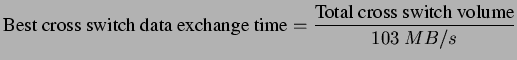Our experimental platform is a cluster consists of 32 standard PCs running Linux 2.2.14. Each cluster node equips with a 733MHz Pentium III processor with 256KB L2 cache, 128MB of main memory, an integrated 3Com 905C FE controller and is connected to the Ethernet-based switched network. Once again, we use the Directed Point communication system to drive the network and conduct all our experiments. In this study, we use four Fast Ethernet switches and one Gigabit Ethernet switch to set up various configurations to evaluate our algorithm.
The GE backbone switch is a chassis switch from Alcatel. It is the
model PowerRail 2200 (PR2200) with backplane capacity reaches 22 Gigabit
per second (Gbps). This switch is equipped with 8 GE ports on 2 modules,
but we only use at most 4 ports in our experiments. Four FE switches
are from IBM, which are of the model 8275-326. It is a 24-port input-buffered
switch with backplane capacity reaches 5 Gbps. A one-port GE uplink
module is installed on each FE switch for connecting to the Gigabit
backbone switch. Table 6.1 summaries all the buffer parameters
of the above switches, which are used in our algorithm to compute
the global windows (![]() ) on different network configurations.
) on different network configurations.
|
To analyze and evaluate the performance of our congestion control
mechanism, we have set up five different configurations on this cluster
- 16X1, 8X2, 8X3, 6X4 and 8X4,
with each configuration corresponds to a different degree of contention
on the uplink ports (except configuration 16X1). The configuration
AXB corresponds to connect A cluster
nodes to each FE switch, and there are total B FE switches
interconnected by the GE switch. This makes up a cluster size of ![]() nodes.
nodes.
The synchronous shuffle exchange is designed to work efficiently on any non-blocking network. However, in previous chapter, we have shown that there is internal constraint on an input-buffered switch, which limits the problem size scalability of our synchronous shuffle exchange algorithm. Although group shuffle exchange is devised to alleviate the problem, it only works sub-optimally from the analytical point of view. In this chapter, we have devised a new congestion control scheme to make synchronous shuffle exchange works efficiently on the hierarchical network. We consider that the same congestion control scheme can be applied to the single-router network to offset the limitation imposed by the HOL blocking.
|
[Measured execution time]
[Achieved bandwidth]
|
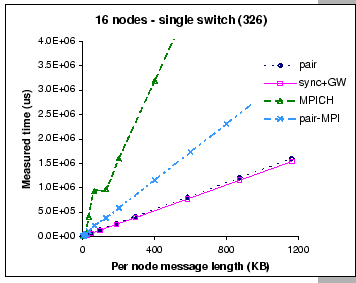
We have shown in Figure 5.6 (Section 5.4) that the performance of the original synchronous shuffle algorithm degrades significantly after k>512, which corresponds to a message length of 746 KB per node. By supplementing the synchronous shuffle algorithm with the global windowing scheme, we show that it continues to operate efficiently as the problem size scales. When compared to the optimal performance (Eq. 5.3), the modified synchronous shuffle exchange algorithm has its efficiency ranged from 87% to 97% of the theoretical bandwidth. When compared with the pairwise exchange, the results show that the modified synchronous shuffle algorithm can effectively mask away synchronization overhead and achieves better performance. This shows that the add-on congestion control scheme does not affect the efficiency of our synchronous shuffle exchange algorithm. Indeed, it effectively guards against the congestion loss.
Not to mention on the poor performance of both MPI implementations, even though we are now using a faster processor and pumping the network with more data, their performances are restrained by the high protocol overheads. Although the pairwise MPI implementation generally performs better than the original MPICH implementation, we observe that the original MPICH implementation is slightly better on small message exchanges. This reflects that the use of non-blocking send and receive operations could hide away part of the synchronization overhead when exchanging small size messages and the induced contention problem is minimal, e.g. the use of eager protocol in the MPICH. However, when exchanging long messages, it would be better to have a well-coordinated schedule.
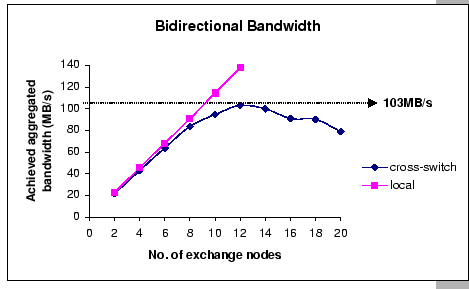
In this subsection, we start our experiments on the hierarchical network by first using a 16-node configuration. We are using two Fast Ethernet switches with eight nodes connect to each switch, and they are interconnected via the Gigabit Ethernet switch. With this setup, the theoretical bisection bandwidth [46] is 1 Gb/s, which should be sufficient for the current cluster configuration.
|
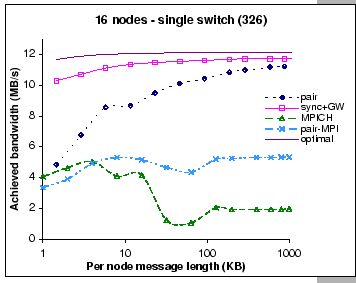
Take an example with the 8X2 configuration, the
total cross-switch volume on the k-item complete exchange is
![]() bytes. Thus, the best timing
in delivering this volume of data across the uplink connection is
bytes. Thus, the best timing
in delivering this volume of data across the uplink connection is
![]() seconds. Assumed that an efficient
communication schedule should be able to arrange all local and cross-switch
communications be happened concurrently. Therefore, the execution
time of the k-item complete exchange should be bounded by the
best cross-switch data exchange time. Then, the best achieved per-node
bandwidth for this k-item complete exchange operation is
seconds. Assumed that an efficient
communication schedule should be able to arrange all local and cross-switch
communications be happened concurrently. Therefore, the execution
time of the k-item complete exchange should be bounded by the
best cross-switch data exchange time. Then, the best achieved per-node
bandwidth for this k-item complete exchange operation is
![]() .
.
![]()
|
[Measured execution time]
[Achieved bandwidth]
|
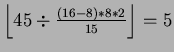 .
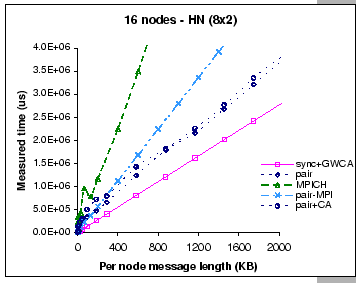
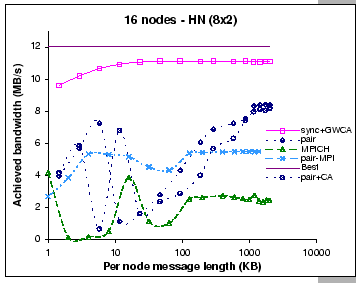
We have measured the performance of the modified synchronous shuffle
algorithm with this global windowing setting, and the results are
presented in Figure 6.7. Similarly, we are comparing different
implementations of the complete exchange operation on this configuration.
Five sets of measurements are shown in the graphs. They are the synchronous
shuffle with global windowing and contention-aware permutation (sync+GW+CA),
pairwise exchange (pair), pairwise exchange with contention-aware
permutation (pair+CA), the original MPICH implementation and the pairwise
exchange MPI implementation (pair-MPI). The results show that synchronous
shuffle exchange with global windowing and contention-aware permutation
performs the best amongst all tested implementations in this configuration.
When compared to the expected best achievement, the modified synchronous
shuffle shows its effectiveness in utilizing the network pipelines
as well as avoiding the congestion loss, since it reaches 93% of
the best achieved performance.
.
We have measured the performance of the modified synchronous shuffle
algorithm with this global windowing setting, and the results are
presented in Figure 6.7. Similarly, we are comparing different
implementations of the complete exchange operation on this configuration.
Five sets of measurements are shown in the graphs. They are the synchronous
shuffle with global windowing and contention-aware permutation (sync+GW+CA),
pairwise exchange (pair), pairwise exchange with contention-aware
permutation (pair+CA), the original MPICH implementation and the pairwise
exchange MPI implementation (pair-MPI). The results show that synchronous
shuffle exchange with global windowing and contention-aware permutation
performs the best amongst all tested implementations in this configuration.
When compared to the expected best achievement, the modified synchronous
shuffle shows its effectiveness in utilizing the network pipelines
as well as avoiding the congestion loss, since it reaches 93% of
the best achieved performance.
However, we find that the performance of the DP pairwise exchange implementation has degraded considerably under this hierarchical configuration when compared to its performance on the single-switch case (Figure 6.5b). Initially, the performance of the DP pairwise implementation (labeled as ``pair'') increases with the increase in message length until the maximum capacity of the uplink ports has reached. After that, the performance is affected by the congestion loss problem. However, our GBN reliable protocol could only recover from the loss with long message exchanges. This is being shown as the slow increased in the achieved bandwidth after experiencing the congestion loss problem. To investigate on whether the contention-aware permutation scheme would also benefit the pairwise exchange algorithm, we have applied the same contention-aware permutation on the DP pairwise implementation. The measured results (labeled as ``pair+CA'') show that this augmentation exhibits a similar behavior as compared to the pure pairwise exchange. However, the congestion loss problem appears earlier than we have expected, and the overall performance is slightly worse than the pure pairwise exchange implementation.
On the other hand, it is interested to see that the performances of the two MPI implementations do not have significant performance changes on this hierarchical configuration. We find that they both have slight improvements on exchanging long message, but the original MPICH implementation has lost its performance on exchanging small messages. This could be the result of contention over the uplinks as the MPICH implementation does not carefully schedule those communication events. This indicates that under this hierarchical configuration, it demands for a better communication scheme to coordinate the communication events, since the performance is limited by the aggregated bandwidth.
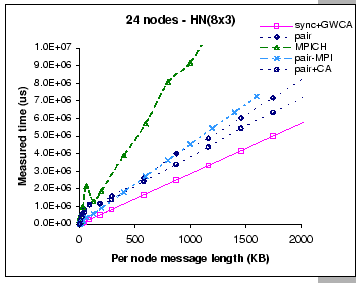
To construct a 24-node cluster with our hardware resources, we can arrange the hierarchical network in two different configurations:
|
[Measured execution time]
[Achieved bandwidth]
|
|
[Measured execution time]
[Achieved bandwidth]
|
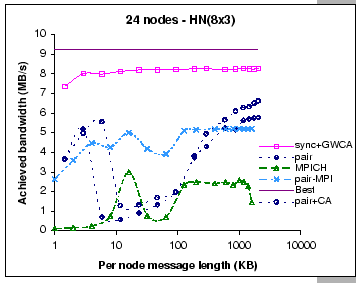
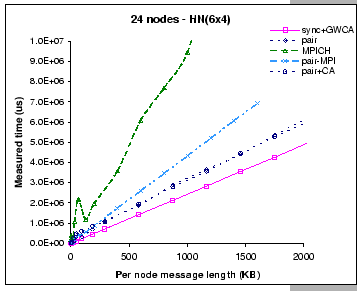
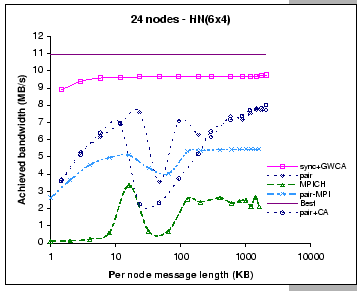
As for the two MPI implementations, their measured performance look similar to the performance observed in the 8X2 configuration. Such that the achieved bandwidth of the pairwise MPI implementation is peaked at 5.4 MB/s and 5.2 MB/s on 6x4 and 8x3 respectively, as compared to 5.5 MB/s on the 8X2 setup. Similarly, the achieved bandwidth of the MPICH implementation is peaked at 2.7 MB/s and 2.6 MB/s on 6X4 and 8X3 respectively, while it achieves 2.7 MB/s on the 8X2 setup. Besides, we observe that as the cluster size has increased from 16 nodes to 24 nodes, the observed contention problem of the original MPICH implementation on small message exchanges is getting worse than the 8X2 configuration. Nevertheless, all these findings support our belief that conventional communication libraries are restrained by the high software overheads.
As for the DP pairwise implementations, their measured results exhibit different performance behaviors on these two configurations. On a configuration that supports less aggregated bandwidth (8X3), we find that we have experienced severe performance loss starting at small size message exchanges. But, with a less restrictive configuration (6X4), the losses start to appear only on medium size message exchanges. After that, the performance slowly increases when exchanging longer messages. On the other hand, we find that the add-on contention-aware scheme (pair+CA) performs better on the 8X3 configuration when compared to the pure pairwise implementation. A possible explanation to this observation is that the contention-aware scheme is more effective when operates on a more stringent configuration.
|
[Measured execution time]
[Achieved bandwidth]
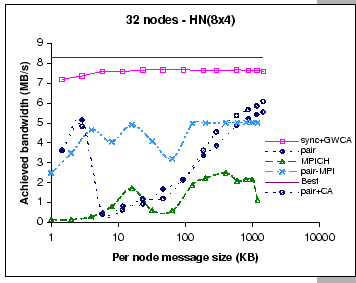
|
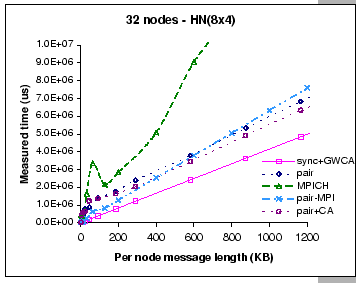
As for the two MPI implementations, their performances closely match with other configurations, which are peaked at 2.5 MB/s on the per-node bandwidth for the MPICH implementation and 5.03 MB/s on the pairwise MPI implementation. However, the performance of our DP pairwise exchange implementation suffers considerably when exchanging small to medium size messages, as the results show that the pairwise MPI implementation outperforms the DP pairwise implementations on this message range. This indicates that our GBN reliable protocol is not working as effectively as the TCP protocol except with large message exchanges. Once again, we observe that the add-on contention-aware permutation on the pairwise implementation has slight performance improvement on the current configuration. When compared this finding with the results on other configurations, we believe that the contention-aware scheme works better on a more stringent configuration. This observation shows that contention-aware permutation alleviates the congestion build-up at the uplink ports; however, it still has to work together with the global windowing scheme in order to avoid congestion loss.